Paths Toward single-slot finality
source: https://notes.ethereum.org/@vbuterin/single_slot_finality
Today, Ethereum blocks take 64-95 slots (~15 minutes) to finalize. This was justified as picking a medium not-bad-on-any-dimension tradeoff on the decentralization / finality time / overhead tradeoff curve: 15 minutes is not too long and it’s comparable to existing exchanges’ confirmation times, it allows users to run nodes on regular computers, even with the large number of validators arising from a deposit size of 32 ETH (as opposed to the earlier value of 1500 ETH). However, there are a lot of good arguments for decreasing the finality time to a single slot. This is a state-of-research post reviewing some possible strategies for doing so.
How and why Ethereum staking works today
Today, there are ~285,000 validators, accounts that have deposited 32 ETH and as a result can participate in staking. Validators do not correspond one-to-one to users: wealthy stakers may control many hundreds of validators. The 32 ETH minimum limits the possible number of validator accounts, ensuring the chain still has the computational capacity to process them.
A new block gets added to the chain every slot (12 seconds). In every slot, there are also thousands of attestations that vote on the head of the chain. There is a fork choice rule called LMD GHOST which takes as input these attestations, and determines the head of the chain. This parallel voting by thousands of attestations makes Ethereum much more robust than a traditional longest-chain system: unless there is an active attack or a huge network mishap, even a single slot is almost never reverted.
The attestations also have a second purpose: they act as votes in a massive consensus algorithm called Casper FFG. Every epoch (32 slots, or 6.4 min), all active validators get a chance to attest once. After two rounds of this, if all goes well, an epoch (and all the blocks inside it) will be finalized. Once a block is finalized, reverting that block requires at least 1/3 of all validators to burn their deposits: a cost of attack of over ~3 million ETH.
Persistently censoring validators or transactions is similarly costly, though defending against censorship attacks requires extra-protocol intervention. If 51% of validators start censoring, the victims and users can coordinate on a minority soft fork where they build on each other’s blocks and ignore the attacker. On the minority soft fork, the attacker’s deposits would lose millions of ETH to an inactivity leak, and after a few weeks the chain resumes finalizing.
Why try to implement single-slot finality?
There are a few key reasons to try to move away from the status quo and bring the finality time down to a single slot:
- User experience. Most users are not willing to wait 15 minutes for finality. Today, even exchanges frequently consider deposits “finalized” after only 12-20 confirmations (~3-5 min), despite the low security assurance (compared to true PoS finalization) that 12-20 PoW confirmations offer. Single-slot finality would provide a very high degree of security at a speed that users are increasingly accustomed to expect.
- MEV reorg resistance. Single-slot finality would make it infeasible for even a majority to reorg the chain for MEV extraction purposes. LMD GHOST in the merge already makes this difficult, but single-slot finality makes this assurance much stronger and creates a strong and overwhelming disincentive deterring even a hostile majority from colluding and attacking. See this post for a more detailed exposition of the argument.
- Opportunity to cut protocol complexity and bugs. The “interface” between Casper FFG finalization and LMD GHOST fork choice is a source of significant complexity, leading to a number of attacks that have required fairly complicated patches to fix, with more weaknesses being regularly discovered. Single-slot finality offers an opportunity to create a cleaner relationship between a single-slot confirmation mechanism and the fork choice rule (which would only run in the offline case). Other sources of complexity (eg. shuffling into fixed-size committees) could also be cut.
Idea 1: single-slot finality through super-committees
Instead of all validators participating in each Casper FFG round, only a medium-sized super-committee of a few thousand validators participates, allowing each round of consensus to happen within a single slot. The technical idea was first introduced in this ethresear.ch post. The post describes the idea in much more detail, but the core principles are as follows:
- Instead of the BFT consensus running every epoch, it runs every slot. This means that once a transaction is included in a block, after a single slot it would cost many thousands of ETH to revert that transaction.
- We don’t rely on the full active validator set to finalize each slot. Instead, we rely on a randomly selected super-committee of a few thousand validators.
- The fork choice rule (LMD GHOST) is only used in the exceptional case where a committee doesn’t confirm (this requires >1/4 to be offline or malicious). If this happens, the fork choice rule governs which block is the head of the chain, and the committee gets inactivity-leaked until it confirms again.
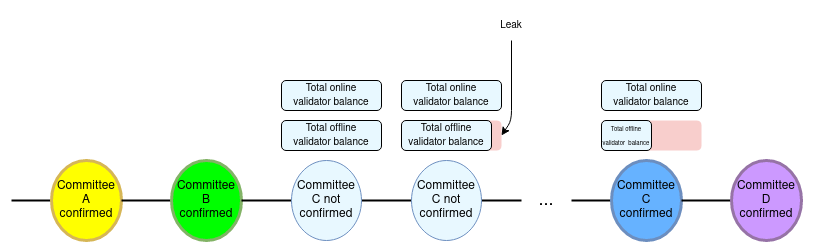
If a committee fails to confirm, the chain keeps progressing using the fork choice to determine the head and the offline validators leak until their balances are diluted to the point where > 2/3 of the remaining validator balances are online the committee can confirm.
Secondary benefits of switching to super-committees
Switching from a global validator set to super-committees has some secondary benefits:
- The computational load of running a validator node becomes more stable. Instead of requirements being proportional to the total validator count, forcing validators to have beefy machines just in case the validator count greatly increases, the computational load will be stable, so validators know exactly what computational requirements they need.
- Most of the time, validators could withdraw instantly. Validators who are not currently part of a committee would be able to withdraw instantly (unless there are very many withdrawals going on and there is a queue). Even validators who are in a committee would be able to withdraw very quickly (1-5 min), because committees could rotate rapidly under single-slot finality. Only in truly exceptional situations (either an unexpected mass exit or an active ongoing attack) would validators be required to stay and continue protecting the chain until everything goes back to normal.
How big do the super-committees have to be?
In terms of validator count, the answer is “big enough to be a secure committee” (so, a few hundred). But the committees also have to be big enough in terms of . The amount of ETH that gets slashed and inactivity-leaked needs to be greater than the revenue that can be realistically gained from an attack, and it needs to be large enough to either deter or bankrupt powerful attackers that have large outside incentives to break the chain.
This question of how much ETH is required is inevitably a matter of intuition. Here are some questions you could ask to guide your intuition:
- Suppose that the Ethereum chain gets 51% attacked and the community needs to spend a few days coordinating an off-chain governance event to recover, but X percent of all ETH gets burned. How large does X need to be for this to be net-good for the Ethereum ecosystem?
- Suppose a major exchange gets hacked for millions of ETH, and the attacker deposits the proceeds and gets over 51% of all validators. How many times should they be able to 51% attack the chain before all their stolen money is burned?
- Suppose that a 51% attacker starts repeatedly re-orging the chain for only a short time to capture all the MEV. What level of cost per second do we want to impose on the attacker?
- Estimates from Justin Drake suggest that the cost of spawn-camp attacking Bitcoin today (so, repeatedly 51% attacking until the community changes the PoW algorithm) is around $10 billion, or 1% of the market cap. How many times that level should the cost of one-time 51% attacking Ethereum be?
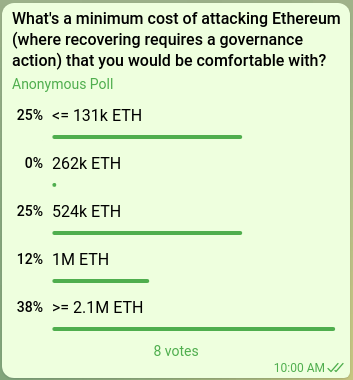
Internal poll among Ethereum researchers.
A 1 million ETH cost of attack would imply a super-committee size of 2 million ETH (~65,536 validators) if we focus only on non-latency-dependent 51% attacks, and 3 million ETH (~97,152 validators) if we also include 34% attacks that involve complicated combinations of malicious validators and network manipulation. But if we want Ethereum chain load to remain the same as it is today (), this would correspond to a cost of attack of 96,000 to 144,000 ETH. There remains a large disparity between these two numbers.
Hence, unless the Ethereum community can be convinced that a lower cost of attacking Ethereum is acceptable (remember: attackers would still need to control over 50% of all staking ETH, this is just the amount they would lose), relying on this path alone seems difficult.
Idea 2: try really hard to make very high attester counts work
Suppose that we actually do want to have a chain with a large number of validators participating per slot (say, 131,072 validators to get a conservative ~4M ETH). How would the performance numbers on that look like?
It turns out that the on-chain costs of having a huge number of validators attesting per slot are less prohibitive than they seem:
- The state space required to store the validator records would be exactly the same as today (~150 bytes per validator)
- Verifying a signature would require adding together a de-facto random subset of 131,072 pubkeys. Each elliptic curve addition could be done in ~1 microsecond, so this could be done in ~130 milliseconds. This would need to be done twice per slot (or possibly a few more times if a block includes redundant attestations)
- On-chain costs (specifically, computing the aggregate pubkey that the signature is verified against) can be optimized further if we assume that a validator who is active in slot N generally stays active in slot N+1; this would mean that for each slot we would only need to compute the delta between the old and new aggregate pubkey, which may consist of a few thousand or even only a few hundred validator pubkeys under good conditions. Even under worst-case conditions, at least 2x optimization (so, ~65 milliseconds) should always be possible.
The biggest problem that remains is signature aggregation. There are 131,072 validators making and sending signatures, and these need to be quickly combined into a single large aggregate signature.
Today, aggregation is done in p2p subnets. Each size-256 committee has signatures aggregated in its own subnet. There are 16 randomly selected privileged aggregators who can make aggregates and submit them to the main subnet. The proposer then takes the best aggregate from each committee, and aggregates those together, making the single grand combined aggregate.
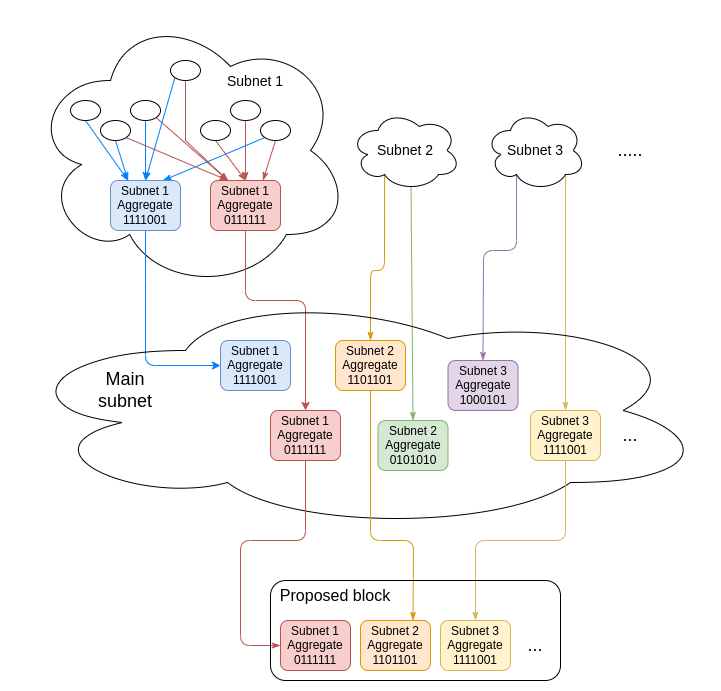
This imposes a load in each subcommittee, where validators need to validate signatures individually (one pairing per signature) particularly in case of attacks flooding the network with invalid signatures, as well as in the global subnet, where the proposer must validate 16 * n signatures if there are n committees.
Aggregation is likely to be a target of significant optimization over the next two years. Currently, the biggest practical bottleneck is the load in each subnet, especially for nodes that need to be in multiple subnets.
Two promising easy paths to get significant improvements are:
- Increase the number of subnets to allow more total attestations without increasing the load per subnet. The load in the main subnet would increase, but this would be compensated for by dank-sharding, which provides efficiencies by allowing all validators in a slot to make signatures over the same data, allowing those signatures to be batch-verified more easily.
- Change networking rules so that even a node with many validators only needs to participate in one subnet, giving room to increase both per-subnet load and subnet count. A validator only strictly needs to be subscribed to a subnet if they are an aggregator in it; a validator that is merely publishing to a subnet need only find an honest peer subscribed to that subnet, and need not subscribe to it themselves.
More specialized aggregators
One possible more radical strategy for supporting far more validators is to turn signature aggregation into a more specialized role (similar to block builders in PBS), where we expect specialized actors to be persistently in many subnets each (or even all subnets) and do a good job of gathering signatures. These actors could be paid, or this could be a volunteer role (as the additional cost is very low for users who are staking many validators already).
A simple protocol for this is to allow validators to sign a ProposedAggregate message containing (i) an aggregate signature, (ii) a bitfield of who participated (only 16 kB assuming 131,072 validators) and (iii) a signature over these two objects signed by the aggregator.
Proposers would listen for ProposedAggregate messages, and verify the signature with the highest participant count. If it is valid, they include it. If the signature is invalid, the proposer would lose up to ~130 milliseconds verifying it and they would move on to verify the second-highest-participation aggregate (and if needed the third-highest, etc), and the aggregator(s) of all invalid ProposedAggregate messages could be slashed.
How do we get there?
Moving to single-slot confirmations is a multi-year roadmap; even if implemented with a large amount of development effort starting soon, it would be one of the later big changes to be added to Ethereum, well after a complete rollout of proof of stake, sharding and Verkle trees. In general, the path to implementation would look roughly as follows:
- Step up work on optimizing attestation aggregation. This is an important problem anyway, as the validator count is expected to increase. We need a more dedicated research and development effort on this problem regardless of what we do for any of the other steps.
- Agree on general parameters: what size of super-committee are we targeting (or would the super-committee be the set of all active validators, and we implement some different mechanism for controlling how many active validators there can be)? What level of overhead are we comfortable with, and what techniques would we use to reduce overhead?
- Research, agree on and specify an ideal consensus and fork choice mechanism for single-slot finality. This would combine together a BFT consensus mechanism (either Casper FFG or something more traditional) and a fork choice rule, where the fork choice rule would only be relevant in the case where of validators are offline.
- Agree on and execute on an implementation path. This could be multi-step, where one step introduces the super-committee mechanism and then the next step adds the full new consensus and aggregation mechanism.
The benefits at the end would be very significant, and the technology could improve over time to achieve other benefits not described here (eg. using the increased maximum validator count to decrease the minimum deposit size). Hence, it’s worth starting deeper and more dedicated research and development on the technical challenges described in this post very soon.